
2026년 3월 25일, 구글 리서치가 발표한 AI 압축 알고리즘 ‘터보퀀트(TurboQuant)’가 글로벌 반도체 시장을 뒤흔들고 있습니다. 발표 다음 날인 26일, 삼성전자 주가는 4% 이상, SK하이닉스는 6% 넘게 급락했고, 미국 마이크론도 3.4% 하락하며 코스피가 3.22% 빠지는 충격이 발생했습니다. AI 메모리 사용량을 6배나 줄일 수 있다는 이 기술, 클라우드플레어 CEO 매튜 프린스는 이를 “구글의 딥시크 모먼트”라고까지 표현했습니다.
과연 이 기술은 정확히 무엇이고, 메모리 반도체 수요에 실제로 어떤 영향을 미칠까요?
1. 구글 터보퀀트란 무엇인가
터보퀀트(TurboQuant)는 구글 리서치, 딥마인드, 뉴욕대, 그리고 KAIST 한인수 교수 연구팀이 공동 개발한 AI 압축 알고리즘입니다. 2026년 4월 ICLR 학회에서 정식 발표될 예정이며, 거대언어모델(LLM)이 추론 과정에서 사용하는 KV 캐시(Key-Value Cache) 메모리를 정확도 손실 없이 최소 6배 압축하는 것이 핵심입니다.
KV 캐시는 LLM이 대화를 이어가거나 긴 문맥을 처리할 때 이전 토큰의 정보를 저장하는 ‘임시 기억장치’ 역할을 합니다. 문맥이 길어질수록 이 캐시의 크기가 기하급수적으로 커지면서 GPU 메모리를 잠식하고 추론 속도를 떨어뜨리는 병목 현상(Memory Wall)이 발생합니다. 700억 파라미터 규모의 LLM을 512명이 동시에 사용하면 KV 캐시만으로 512GB의 메모리가 필요한데, 이는 모델 가중치의 약 4배에 달하는 수치입니다.
이 압축 알고리즘은 이 KV 캐시를 3비트 수준으로 압축하면서도 모델 성능을 온전히 유지합니다. 엔비디아 H100 GPU 기준으로 어텐션 로짓 연산 속도를 최대 8배 높이는 성과도 보여줬습니다.
2. 구글 터보퀀트의 작동 원리: 폴라퀀트와 QJL의 이중 구조
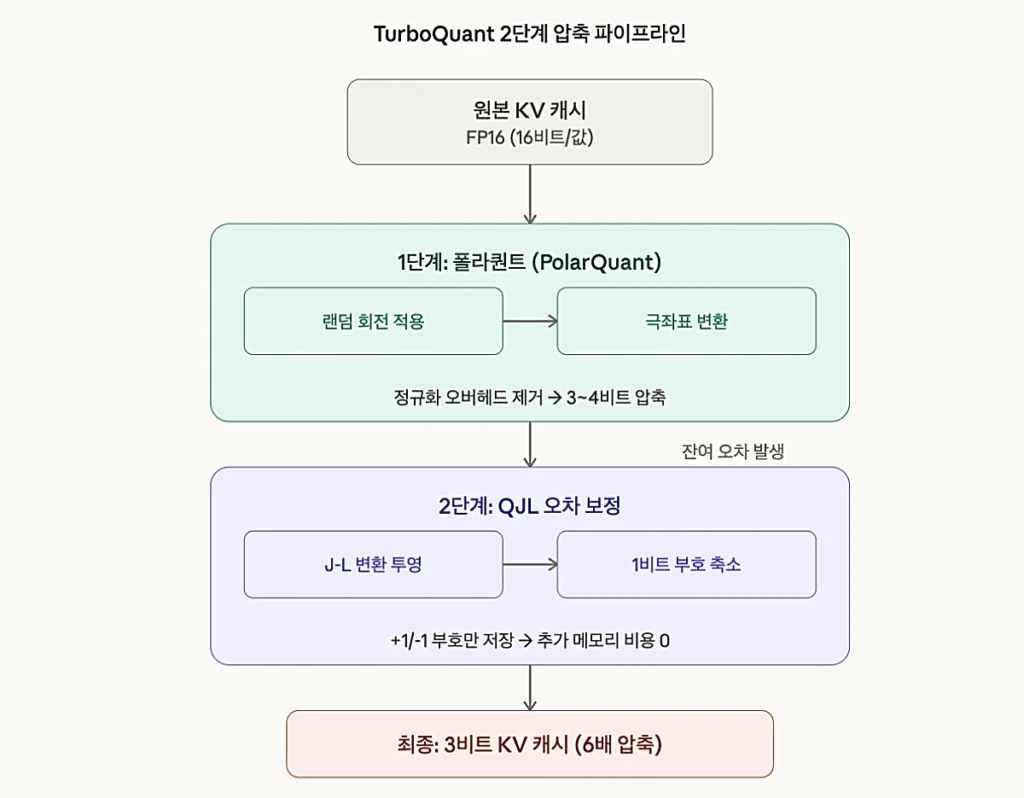
이 기술이 획기적인 이유는 기존 양자화 기술의 고질적 한계를 수학적으로 해결했기 때문입니다. 기존 벡터 양자화 기술은 데이터를 압축할 때 블록마다 ‘양자화 상수(Quantization Constants)’를 별도로 저장해야 했습니다. 이 상수가 수치당 1~2비트의 추가 메모리 오버헤드를 발생시켜, 겉으로는 압축해도 실질적인 절감 효과가 줄어드는 문제가 있었습니다.
이 알고리즘은 폴라퀀트(PolarQuant)와 QJL(Quantized Johnson-Lindenstrauss)이라는 두 가지 기법을 결합하여 이 문제를 근본적으로 해결합니다.
| 구성 요소 | 역할 | 핵심 원리 |
|---|---|---|
| 폴라퀀트(PolarQuant) | 고품질 압축(1차 압축) | 직교좌표를 극좌표로 변환해 데이터 구조를 단순화, 블록별 정규화 오버헤드 제거 |
| QJL | 오차 보정(2차 보정) | 존슨-린덴스트라우스 변환으로 잔여 오차를 1비트 부호(+1/-1)로 축소, 추가 메모리 비용 제로 |
| 통합 프레임워크(TurboQuant) | 통합 프레임워크 | 폴라퀀트 + QJL 결합으로 정확도 무손실 6배 압축 달성 |
폴라퀀트는 기존에 직교좌표(Cartesian) 방식으로 저장하던 고차원 벡터를 극좌표(Polar) 방식으로 변환합니다. 쉽게 말하면, 소수점이 길게 이어지는 복잡한 숫자를 반지름(크기)과 각도(방향)로 분리하여 훨씬 단순한 형태로 표현하는 것입니다. 이렇게 변환하면 각도 분포가 예측 가능하고 집중되기 때문에 기존처럼 매 블록마다 정규화 상수를 따로 저장할 필요가 사라집니다.
QJL은 폴라퀀트 압축 후 남은 미세한 오차를 보정하는 역할을 합니다. 존슨-린덴스트라우스 변환이라는 수학적 기법을 사용해 잔여 오차 벡터를 단 1비트의 부호(+1 또는 -1)로 줄입니다. 이 과정에서 데이터 간의 거리와 관계가 보존되므로, 모델이 어텐션 스코어(어떤 단어가 중요한지 판단하는 과정)를 계산할 때 압축 전과 통계적으로 동일한 결과를 얻을 수 있습니다.
무엇보다 이 기술의 가장 큰 장점은 ‘데이터 비의존적(data-oblivious)’이라는 점입니다. 별도의 학습이나 캘리브레이션 없이 어떤 모델에든 바로 적용할 수 있어, 기업들이 기존에 파인튜닝한 모델을 재학습 없이 즉시 메모리를 절감할 수 있습니다.
3. 이 기술이 메모리 수요를 줄이는 이유
이 기술이 메모리 수요에 영향을 미치는 핵심 경로는 AI 추론(Inference) 단계의 메모리 효율화입니다. 현재 AI 서비스가 급성장하면서 GPU에 탑재되는 고대역폭메모리(HBM)의 수요도 폭발적으로 늘어나고 있는데, KV 캐시가 차지하는 메모리 비중이 상당하기 때문입니다.
구글은 이 압축 기술을 자사 AI 모델 제미나이(Gemini)의 KV 캐시 병목 해소에 적용하고, 검색 엔진의 벡터 검색에도 활용할 계획이라고 밝혔습니다. 만약 이 기술이 업계 전반에 확산된다면, 같은 양의 HBM으로 더 많은 사용자를 처리하거나 더 긴 문맥을 다룰 수 있게 되므로, 단위 서비스당 필요한 메모리 칩의 수가 줄어들 가능성이 있습니다.
실제로 구글의 벤치마크 테스트에서 이 알고리즘은 Gemma, Mistral 등 오픈소스 LLM에 적용했을 때 Needle-in-a-Haystack(10만 단어 속 특정 문장 찾기) 테스트에서 완벽한 정확도를 기록하면서 KV 캐시 메모리를 6분의 1로 줄였습니다. LongBench, ZeroSCROLLS, RULER 등의 벤치마크에서도 기존 KIVI 기법 대비 동등하거나 우수한 성능을 보여줬습니다.
4. 메모리 기업 투자 전망: 위기인가, 기회인가
이 기술 발표 직후 시장의 반응은 즉각적이었습니다. 삼성전자, SK하이닉스, 마이크론 등 주요 메모리 기업의 주가가 동반 하락했고, 코스피 지수도 3.22% 빠졌습니다. 투자자들 사이에서 메모리 반도체 슈퍼사이클이 꺾이는 것 아니냐는 우려가 빠르게 확산됐습니다.
그러나 증권가와 반도체 업계에서는 이번 하락이 과도한 반응이라는 분석이 지배적입니다. 그 근거는 크게 세 가지로 정리할 수 있습니다.
| 관점 | 위기론 | 기회론 |
|---|---|---|
| 기술 성숙도 | 논문 발표로 상용화 임박 | 아직 논문 단계, 공식 오픈소스 코드 미공개 |
| 수요 영향 | 단위당 메모리 사용량 감소 | 절대적 AI 메모리 수요가 기하급수적으로 증가 중 |
| 역사적 선례 | 효율화가 수요 감소로 이어질 수 있음 | 제번스의 역설: 효율 개선이 오히려 총수요 확대 |
| 적용 범위 | 추론 메모리 전반에 영향 | KV 캐시만 대상, 학습(Training) 메모리에는 무관 |
| 업계 채택 | 구글이 선도하면 확산 빠를 것 | 모든 빅테크가 구글 기술을 채택하지는 않음 |
1) 논문 단계의 기술
공식 오픈소스 코드가 공개되지 않았고, 커뮤니티에서 자체 구현을 시도하고 있지만 QJL 오차 보정 구현이 까다로워 제대로 작동하지 않는 사례도 보고되고 있습니다. 벤치마크 테스트도 80억 파라미터 수준의 모델에서만 진행되었으며, 700억 이상 대형 모델에서의 성능은 아직 검증되지 않았습니다.
2) 제번스의 역설(Jevons Paradox)이 반복될 가능성
과거에도 GPU 효율이 개선될 때마다 전체 GPU 수요가 줄어들기는커녕 오히려 늘어났습니다. 딥시크 V2가 20분의 1 비용으로 LLM을 학습시켰다는 소식에 시장이 공포에 빠졌지만, 이후 AI 시장 확장세는 오히려 가속화됐습니다. 메모리 효율이 높아지면 기업들은 그 여유분을 더 거대한 모델, 더 긴 문맥, 더 많은 사용자 처리에 재투자할 가능성이 큽니다.
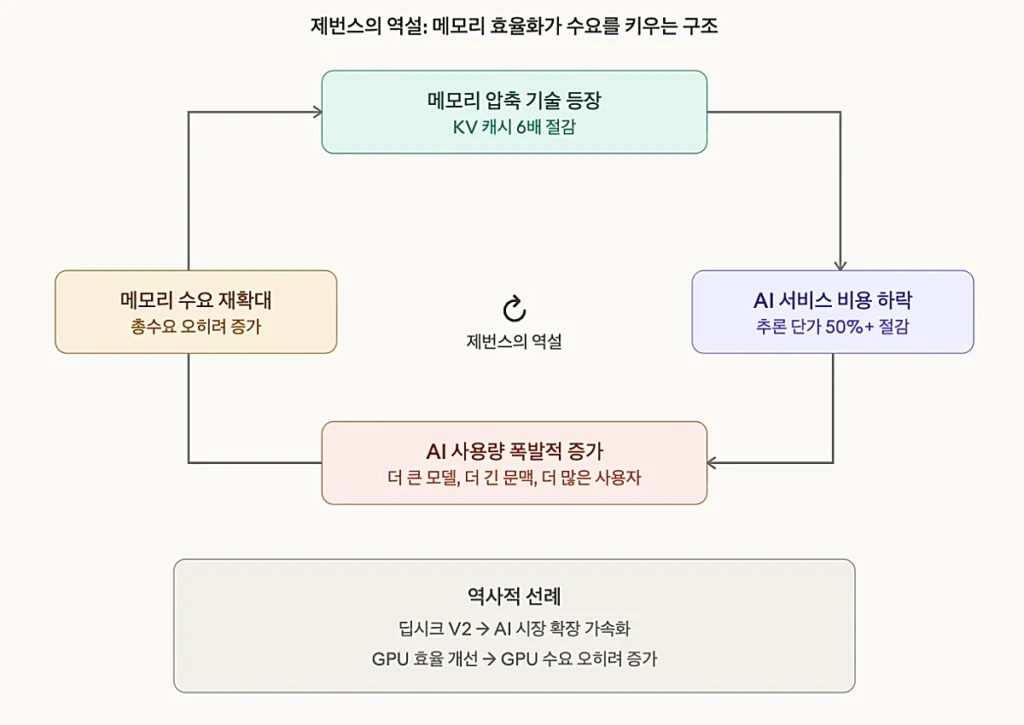
3) 이 압축 기술은 추론 단계의 KV 캐시만을 대상으로 함
AI 학습에 필요한 대규모 메모리 수요는 이 기술의 영향권 밖입니다. 현재 AI 인프라 투자의 상당 부분이 학습용 데이터센터 확장에 집중되어 있다는 점을 감안하면, 전체 메모리 수요에 대한 타격은 제한적이라는 분석입니다.
KB증권 연구원은 추론 단가가 하락하면서 AI 에이전트 시장의 성장세가 가속화할 것이라고 전망했습니다. 키움증권 연구원도 이번 이슈가 연초 메모리 급등 랠리에 따른 피로도와 맞물려 차익 실현의 명분으로 작용한 측면이 크다고 분석했습니다.
5. 투자자가 주목해야 할 포인트
이 기술이 투자 판단에 미치는 영향을 정리하면 다음과 같습니다.
단기적으로는 메모리 반도체 주가에 하방 압력이 작용할 수 있습니다. 특히 이 기술이 ICLR 2026 학회(4월)에서 정식 발표되는 시점을 전후로 시장 변동성이 커질 가능성이 있습니다. 단기 트레이딩 관점에서는 이벤트 전후 리스크 관리가 필요합니다.
중장기적으로는 메모리 반도체 수요의 구조적 성장 추세가 유지될 가능성이 높습니다. AI 모델의 거대화, 에이전틱 AI의 확산, 온디바이스 AI 시대의 도래 등 메모리 수요를 견인하는 거시적 트렌드가 여전히 강력하기 때문입니다. 오히려 이 같은 효율화 기술이 AI 서비스의 진입 장벽을 낮추어 시장 자체를 키우는 촉매가 될 수도 있습니다.
다만 메모리 산업의 경쟁 구도는 변화할 수 있습니다. 단순히 용량이 큰 메모리 칩을 만드는 것이 아니라, 효율적인 메모리 아키텍처와 소프트웨어-하드웨어 통합 능력이 더욱 중요해지는 ‘지능 경쟁’ 시대로 전환될 가능성이 있습니다. 투자자들은 메모리 기업을 평가할 때 단순 생산 능력보다 기술 혁신 역량과 AI 생태계 내 위치를 함께 고려할 필요가 있습니다.
자주 묻는 질문
터보퀀트는 2026년 4월 ICLR 학회에서 정식 발표될 예정이며, 현재까지 공식 오픈소스 코드는 공개되지 않은 상태입니다. 커뮤니티에서 Triton, MLX, llama.cpp 등으로 자체 구현을 시도하고 있지만, 실제 프로덕션 환경의 주요 서빙 프레임워크(vLLM, Ollama 등)에는 아직 통합되지 않았습니다. 구글이 자사 제미나이 서비스에 먼저 적용한 뒤 점진적으로 확산될 것으로 예상됩니다.
증권가의 주류 의견은 과도한 우려라는 쪽입니다. 이 기술은 추론용 KV 캐시만 대상으로 하며, AI 학습 메모리 수요에는 영향이 없습니다. 역사적으로 효율화 기술은 비용을 낮추어 더 많은 수요를 창출하는 제번스의 역설이 반복되어 왔습니다. 다만 단기 변동성에는 대비할 필요가 있습니다.
딥시크는 적은 비용으로 LLM을 학습시키는 효율화 기술이었고, 이번 구글의 알고리즘은 AI 추론 단계에서 KV 캐시 메모리를 압축하는 기술입니다. 두 기술 모두 소프트웨어적 최적화로 하드웨어 의존도를 줄인다는 공통점이 있어 “구글의 딥시크 모먼트”로 비유되지만, 적용 영역이 학습과 추론으로 서로 다릅니다.
결론
구글 터보퀀트는 AI 인프라의 핵심 병목인 메모리 문제에 대한 소프트웨어적 해법으로, 메모리 반도체 업계에 단기적 충격을 준 것은 사실입니다. 그러나 아직 논문 단계이며, 효율화 기술이 오히려 전체 시장을 키우는 역사적 패턴(제번스의 역설)을 감안하면 장기적 메모리 수요 전망을 바꿀 만한 수준은 아니라는 것이 업계의 중론입니다.
투자자라면 단기 변동성에 흔들리기보다, AI 인프라 확장이라는 구조적 성장 트렌드 속에서 기술 혁신 역량을 갖춘 메모리 기업의 경쟁력을 냉정하게 재평가하는 기회로 삼을 필요가 있습니다.
이 포스팅은 정보 제공 목적으로 작성했습니다. 투자 판단은 본인의 몫이며, 투자 결과에 따른 책임은 투자자 본인에게 있습니다.
Recommendation 포스팅
Add your first comment to this post