
AI를 주식 투자에 활용하는 다양한 방법이 시도되고 있습니다. 주로 자료 조사나 리서치에 대한 내용이 많은데요. 그러다 문득 “AI가 기술적 분석을 잘할까? 만약 잘한다면 AI의 도움을 받아 투자 성공률을 높일 수 있지 않을까?” 하는 궁금증이 생겼습니다. 이렇게 시작된 실험을 같이 공유하고자 합니다.
기술적 분석을 위해서 정확한 주가 데이터가 필요한데요. 저는 5분봉 데이터를 수집해서 이용해보려고 합니다. 이 포스팅에서는 파이썬을 활용해서 5분봉 주가 데이터를 수집하는 방법을 공유하겠습니다.
5분봉 주가 데이터 수집 방법 비교
제가 알아본 5분봉 주가 데이터를 수집하는 방법은 세 가지가 있습니다. 증권사 API 활용, 야후 파이낸스 데이터 이용, 그리고 네이버 금융 크롤링인데요. 각각의 장단점을 살펴보고 왜 저는 네이버 크롤링을 선택했는지 설명 드릴게요.
첫째, 증권사 API는 가장 정확하고 안정적인 데이터를 제공합니다. 키움증권, 대신증권 등 많은 증권사들이 API 서비스를 제공하고 있죠. 하지만 이를 이용하려면 해당 증권사의 계좌가 필요합니다. 저는 현재 사용 중인 증권사 API가 없어서 이 방법은 패스했습니다.
둘째, 야후 파이낸스는 yfinance 패키지를 통해 쉽게 접근할 수 있습니다. 많은 분들이 활용하는 인기 있는 방법이죠. 코드도 간단하고 사용 방법도 직관적입니다. 하지만 문제가 있었는데요. 한국 주식 5분봉 데이터는 거래 내역을 오후 3시까지만 제공했습니다. 장 종료 직전 데이터가 누락돼 이 방법은 제외했습니다.
셋째, 네이버 금융 크롤링은 위 두 방법의 한계를 극복하는 대안입니다. 네이버 금융은 16시까지 체결 데이터를 확인할 수 있습니다. 지금은 대체 거래소가 생겨서 20시까지 거래가 가능하지만, 가장 거래가 활발한 시간대 데이터는 수집할 수 있습니다.
파이썬으로 네이버 금융 5분봉 크롤링하기
제가 작성한 코드는 github에 올렸습니다. 이를 이용해서 삼성전자 하루치 데이터를 수집하는 코드도 코랩에 만들었으니 참고하세요.
– https://github.com/tariat/TariatStock/tree/main
코랩에서 코드를 실행하면 아래와 같이 5분봉 데이터가 수집됩니다.
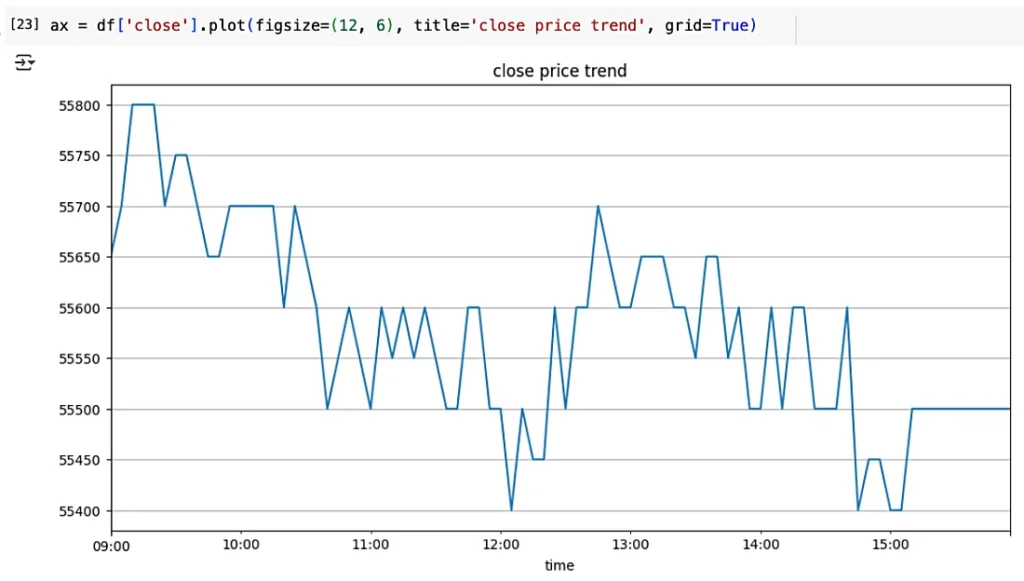
종가를 기준으로 차트도 그려봤습니다.
코랩 노트북 파일은 아래 링크에서 확인할 수 있습니다.
– https://colab.research.google.com/drive/1yDQmwi2IWPOIjrh_gqZwKhe_gFxZDMZ7?usp=sharing
데이터는 ProjectAuto라는 폴더를 만들고, sqlite3 db로 데이터를 만들어 저장합니다. 코랩에서 실행하면, 데이터가 사라져서 매번 다시 수집해야 합니다. 가급적 코드를 저장해서, 내 컴퓨터에서 실행하는 걸 추천합니다.
5분봉 주가 데이터를 수집하는 코드 상세 내용은 아래와 같습니다. sqlite3 db를 저장하는 경로를 코드로 가져와서 그대로 실행하면 에러가 납니다. db 경로를 다른 경로로 직접 지정해서 사용하면 됩니다.
import pandas as pd
import requests
from bs4 import BeautifulSoup
import time
import os
from io import StringIO
from tqdm import tqdm
from autils import data_dir
from autils.db import SqLite
db = SqLite(f"{data_dir}/stock_5m_data.db")
# SQLite 데이터베이스 테이블 생성
def init_db():
"""
SQLite 데이터베이스와 테이블을 초기화합니다.
"""
# 주식 5분봉 데이터를 저장할 테이블 생성
db.execute('''
CREATE TABLE IF NOT EXISTS stock_5m_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT NOT NULL,
date TEXT NOT NULL,
time TEXT NOT NULL,
open REAL,
high REAL,
low REAL,
close REAL,
volume INTEGER,
trading_value REAL,
UNIQUE(code, date, time)
)
''')
def crawl_date_by_date(code, date):
"""
date: yyyymmdd
"""
url = f"http://finance.naver.com/item/sise_time.nhn?code={code}&thistime={date}180000&page=1"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
table = soup.find("table")
temp = pd.read_html(StringIO(soup.decode_contents()))[0]
temp.dropna(inplace=True)
last_page_num = soup.select(".pgRR")[0].select("a")[0].get_attribute_list("href")[0].split("=")[-1]
last_page_num = int(last_page_num)
df_lst = list()
df_lst.append(temp)
def get_table_by_page(code, date, page):
url = f"http://finance.naver.com/item/sise_time.nhn?code={code}&thistime={date}180000&page={page}"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
table = soup.find("table")
temp = pd.read_html(StringIO(soup.decode_contents()))[0]
temp.dropna(inplace=True)
time.sleep(1)
return temp
for p in tqdm(range(2, last_page_num+1)): # 여기 range로 수정했습니다
df_lst.append(get_table_by_page(code, date, p))
total = pd.concat(df_lst, axis=0)
total['체결시각'] = date + " " + total['체결시각']
return total
def create_5min_candle(df):
# 체결시각 컬럼을 datetime 형식으로 변환
df['체결시각'] = pd.to_datetime(df['체결시각'], format='%Y%m%d %H:%M')
# 인덱스를 리셋하고 체결시각을 인덱스로 설정
df = df.reset_index(drop=True).set_index('체결시각')
df['거래대금'] = df['변동량'] * df['체결가']
# 5분 간격으로 리샘플링
resampled = pd.DataFrame()
# 시가 (첫 체결가)
resampled['시가'] = df['체결가'].resample('5min').first()
# 고가 (최대 체결가)
resampled['고가'] = df['체결가'].resample('5min').max()
# 저가 (최소 체결가)
resampled['저가'] = df['체결가'].resample('5min').min()
# 종가 (마지막 체결가)
resampled['종가'] = df['체결가'].resample('5min').last()
# 거래량 (거래량 차이)
resampled['거래량'] = df['거래량'].resample('5min').first() - df['거래량'].resample('5min').last()
resampled['거래량'] = resampled['거래량'].abs() # 양수로 변환
# 거래대금
# 거래대금 = 거래량 * 평균가격
resampled['거래대금'] = df['거래대금'].resample('5min').sum()
# 결측값 처리
resampled = resampled.ffill()
# 인덱스를 컬럼으로 변환하여 반환
resampled = resampled.reset_index()
return resampled
def save_to_db(code, date, df):
"""
5분봉 데이터를 SQLite DB에 저장합니다.
"""
for _, row in df.iterrows():
time_str = row['체결시각'].strftime('%H:%M')
date_str = row['체결시각'].strftime('%Y%m%d')
db.execute('''
INSERT OR REPLACE INTO stock_5m_data
(code, date, time, open, high, low, close, volume, trading_value)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
code,
date_str,
time_str,
row['시가'],
row['고가'],
row['저가'],
row['종가'],
row['거래량'],
row['거래대금']
))
def get_5m_from_db(code, date):
"""
DB에서 특정 종목, 특정 날짜의 5분봉 데이터를 조회합니다.
"""
query = '''
SELECT time, open, high, low, close, volume, trading_value
FROM stock_5m_data
WHERE code = ? AND date = ?
ORDER BY time
'''
df = db.get(query, params=(code, date))
if not df.empty:
# 시간 데이터 형식 조정
df['time'] = pd.to_datetime(date + ' ' + df['time'])
df = df.set_index('time')
return df
def get_5m_by_date(code, date):
"""
특정 종목, 특정 날짜의 5분봉 데이터를 가져옵니다.
DB에 있으면 DB에서 가져오고, 없으면 크롤링 후 DB에 저장합니다.
"""
# 먼저 DB에서 데이터 조회
df = get_5m_from_db(code, date)
# DB에 데이터가 없으면 크롤링하여 저장
if df.empty:
raw_df = crawl_date_by_date(code, date)
df = create_5min_candle(raw_df)
save_to_db(code, date, df)
df = df.rename(columns = {
"체결시각":"time",
"시가":"open",
"고가":"high",
"저가":"low",
"종가":"close",
"거래량":"volume",
"거래대금":"trading_value"})
return df
if __name__=="__main__":
# DB 초기화
init_db()
# 데이터 가져오기
df = get_5m_by_date("005930", "20250428")
print(df.head())
get_5m_by_date 함수 입력 파라미터로 종목코드와 날짜를 넣으면, 해당 일 5분봉 주가 데이터를 제공합니다. 코드에 대한 상세 설명은 생략합니다.
데이터 활용
데이터를 성공적으로 수집해서, 이제 인공지능에게 분석을 요청해봤습니다. 5분봉 데이터를 그대로 제공하고, 투자 판단과 그 근거를 확인해봤는데요. 인공지능이 내린 결정으로 백테스팅도 진행했습니다. 자세한 내용은 아래 포스팅을 참고하세요.

Recommended Posts
- 클로드 AI로 주식 MCP 사용하기
- 엔비디아 AI PC 특징과 출시 계획
- 오픈AI 주식에 투자하는 현실적인 3가지 방법
- 앱트로닉 주가 및 투자하는 방법 – 딥마인드 협력 로봇기업
- AI와 다른 프로그램을 연결하는 클로드 MCP 설정 및 시작 방법
Add your first comment to this post